
HTTP steht für Hypertext Transfer Protocol. Es handelt sich um ein Anwendungsprotokoll auf der Anwendungsschicht, das nach dem Request-Response-Prinzip für das Web funktioniert. HTTP basiert auf einer Client-Server-Architektur, die den zuverlässigen Austausch von Ressourcen zwischen einem Webanwendungsserver und einem User Agent (UA) – wie z. B. einem Webbrowser – ermöglicht. Zu den UAs zählen auch Webcrawler, mobile Apps und andere Software, die auf Webressourcen zugreift.
HTTP wurde entwickelt, um die Kommunikation zwischen Geräten und Anwendungen im Web zu erleichtern. Es definiert, wie Anfragen nach Inhalten formatiert und übertragen werden und wie Antworten aufgebaut sind. HTTP überträgt Inhalte wie Text, Bilder, Audio und Video mithilfe eines Protokollstapels namens Transmission Control Protocol/Internet Protocol (TCP/IP).
Im Laufe der Entwicklung von HTTP wurden mit jeder Version neue Funktionen hinzugefügt. Jede Version behandelt bestimmte Prozesse – wie z. B. das Verbindungsmanagement – auf unterschiedliche Weise.
Tim Berners-Lee, der als Begründer des Internets gilt, schrieb die erste Version von HTTP. Die Spezifikationen für HTTP, Hypertext Markup Language (HTML) und Uniform Resource Identifier (URI) wurden zwischen 1989 und 1990 geschrieben. Der erste Webserver wurde 1991 in Betrieb genommen.
Ein Internetprotokoll ist eine Sammlung von Regeln, die festlegen, wie Geräte in einem Internetnetzwerk miteinander kommunizieren. Diese Regeln basieren auf gemeinsamen Standards, die durch sogenannte Request for Comments (RFCs) definiert werden. RFCs bilden die Grundlage für die Standards, die bei der Netzwerkkommunikation im Internet verwendet werden. Sie werden von der Internet Engineering Task Force (IETF) verwaltet – dem wichtigsten Gremium zur Festlegung von Standards für die Funktionsweise des Internets. Beispiele für gängige Netzwerkprotokolle sind HTTP, TCP, IP, FTP und Secure Shell (SSH).
Netzwerkprotokolle lassen sich weiter untergliedern. Das Open Systems Interconnection (OSI)-Modell ist ein konzeptioneller Rahmen, der die Funktionen eines Computersystems beschreibt. Es besteht aus sieben Schichten: physikalisch, Sicherung, Netzwerk, Transport, Sitzung, Darstellung und Anwendung. Die Daten jeder Schicht werden durch unterschiedliche Protokolle verarbeitet. HTTP ist ein Protokoll der Schicht 7 (Anwendungsschicht) und darf nicht mit der Netzwerkschicht des OSI-Modells verwechselt werden.
Daten im Internet werden über einen Stapel von Netzwerkprotokollen verwaltet und übertragen, der als TCP/IP bezeichnet wird. Jede Schicht in diesem Protokollstapel lässt sich dem OSI-Modell zuordnen und erfüllt eine bestimmte Funktion. HTTP gehört zur Anwendungsschicht und ermöglicht die Kommunikation zwischen verschiedenen Anwendungen. Es verwendet TCP, um Sitzungen zwischen einem Client und einem Server aufzubauen. TCP gehört zur Transportschicht im Stapel. Es unterteilt Nachrichten am Ursprungsort in Datenpakete, die am Zielort wieder zusammengesetzt werden. Das IP im Akronym TCP/IP steht für das Protokoll, das Datenpakete mithilfe einer IP-Adresse gezielt an einen bestimmten Computer weiterleitet. IP gehört zur Netzwerkschicht.
Theoretisch könnte HTTP auch ein alternatives Transportprotokoll wie UDP verwenden, aber HTTP nutzt fast immer TCP, da es verbindungsorientiert und zuverlässiger als UDP ist. TCP wird bevorzugt bei Anwendungen eingesetzt, bei denen die Daten zuverlässig, relevant und vollständig übertragen werden müssen – zum Beispiel bei einer Nachrichtenseite. UDP ist ein verbindungsloses Protokoll und kann verlorene Datenpakete nicht erneut senden. Dafür ist UDP schneller als TCP und wird häufig bei Anwendungen wie Videokonferenzen oder Streaming verwendet, wo kleinere Übertragungsfehler kaum auffallen. Die neueste Entwurfsfassung von HTTP, HTTP/3, geht jedoch auf einige der Probleme von TCP und UDP ein. Sie kombiniert Funktionen aus zwei Protokollen: HTTP/2 und QUIC über UDP. HTTP/3 wird daher auch als HTTP-over-QUIC bezeichnet.
QUIC ist ein Netzwerkprotokoll, das als Alternative zur Kombination aus TCP, Transport Layer Security (TLS) und HTTP/2 dient. Es wird auf Basis von UDP implementiert. QUIC überträgt HTTP/3-Daten effizienter und schneller über UDP als ältere HTTP-Versionen, die auf TCP basieren. QUIC reduziert die Verbindungs-Latenz, verbessert die Staukontrolle, erlaubt Multiplexing ohne Head-of-Line-Blocking, unterstützt Forward Error Correction und ermöglicht Connection Migration. QUIC ist standardmäßig vollständig mit TLS 1.3 verschlüsselt. Da UDP verbindungslos ist, besteht eine der Hauptaufgaben von QUIC darin, die Verbindungszuverlässigkeit sicherzustellen – etwa durch die Möglichkeit, verlorene Pakete erneut zu übertragen.
Die erste Version von HTTP unterstützte nur die GET-Methode und enthielt keine Header, Metadaten wie Content-Typen oder Statuscodes. Da HTTP/0.9 keine Header verwendete, konnten nur HTML-Seiten (Hypertext) an den Client zurückgegeben werden. Nach Erhalt einer Serverantwort wurde die Verbindung vom Client sofort geschlossen. HTTP/0.9 ist heute größtenteils veraltet, wird aber von einigen bekannten Webservern wie nginx weiterhin unterstützt.
HTTP/1.0 unterstützte die GET- und POST-Methoden sowie Versionsangaben und Statuscodes. Es wurden Header eingeführt, mit denen ein Content-Typ angegeben werden konnte, sodass auch andere Dateien als HTML übertragen werden konnten. Auch hier wurde die Verbindung vom Client direkt nach der Serverantwort geschlossen. Die Einführung von Headern machte HTTP sehr erweiterbar.
Beim Laden einer Webseite müssen mehrere Bestandteile wie Text, Bilder oder Videos separat abgerufen werden. Jeder dieser Inhalte besitzt eine eigene URL und erfordert eine eigene Anfrage. In HTTP/1 bedeutete das, dass mehrere einzelne Verbindungen zum Server aufgebaut werden mussten. HTTP/1.1 führte persistente Verbindungen und Pipelining ein:
Dies ermöglichte die Übertragung mehrerer Inhalte (z. B. Bilder) über eine einzige Verbindung, was die Latenzzeit reduzierte.
HTTP/1.1 unterstützte außerdem neue Methoden wie DELETE, PUT und TRACE und brachte Funktionen wie Caching, Cookies, kodierte Übertragungen und Content Negotiation (automatische Auswahl des besten Inhaltsformats oder Sprache zwischen Client und Server). HTTP/1.1 machte die Standardisierung robuster und ist heute die am weitesten verbreitete Version von HTTP.
Basierend auf SPDY, einem von Google entwickelten, inzwischen veralteten Protokoll, sollte HTTP/2 die Ladezeiten von Webseiten verringern und die Sicherheit verbessern. HTTP/1.1 war ressourcenintensiv, besonders hinsichtlich der CPU-Auslastung. HTTP/2 brachte die fortschrittliche Multiplexing-Technologie, mit der mehrere Datenströme gleichzeitig über eine einzige Verbindung übertragen werden können – mithilfe von HTTP-Frames und HTTP-Streams.
Das Head-of-Line-Blocking in HTTP/1.1 wurde so verringert: Wenn eine Anfrage blockiert ist, behindert das nicht länger nachfolgende Anfragen. Während HTTP/1.1 Anfragen und Antworten im Textformat verarbeitet, verwendet HTTP/2 ein binäres Format. Nachrichten werden in logische Einheiten wie Header-Frames und Daten-Frames unterteilt, die über eine gemeinsame Stream-ID identifiziert werden. HTTP/2 erlaubt mehrere Streams über eine Verbindung und ermöglicht auch, dass mehrere Antworten gleichzeitig zurückgesendet werden. Weitere Funktionen:
Laut W3Techs wird HTTP/2 von etwa 46 % der Webseiten verwendet. Es ist nicht rückwärtskompatibel zu älteren HTTP-Versionen.
HTTP/3 verbessert die Leistung von HTTP/2 und behebt einige seiner Schwächen. Es basiert auf dem Transportprotokoll UDP statt auf TCP. Ein wesentlicher Vorteil: Head-of-Line-Blocking auf TCP-Ebene wird vermieden. Wenn bei TCP ein Paket verloren geht, müssen alle folgenden warten. HTTP/3 ist durch UDP schneller, da es keine IP-Adresse zur Verbindung benötigt, sondern Verbindungs-IDs verwendet – so bleiben Downloads stabil, auch bei Netzwerkwechseln.
Anders als bei TCP, wo eine Verbindung per Dreifach-Handshake aufgebaut wird, braucht UDP nur eine Hin- und Rückübertragung. Außerdem:
Mit benutzerdefinierten Warnmeldungen und Datenvisualisierung können Sie Probleme mit dem Netzwerkzustand und der Leistung schnell erkennen und vermeiden.
Header machen HTTP erweiterbar, da Client und Server vereinbaren können, neue Feldnamen und Informationen hinzuzufügen, die ihren Bedürfnissen entsprechen.
Obwohl es möglich ist, muss ein HTTP-Server keine Informationen zwischen den Anfragen speichern. Diese Eigenschaft machte frühe HTTP-Versionen zustandslos ("stateless"). In den Versionen vor HTTP/2 wurden Anfragen unabhängig voneinander gestellt, ohne zu wissen, was in den vorherigen Anfragen passiert ist. HTTP wurde vor allem aus Gründen der Skalierbarkeit als zustandsloses Modell entwickelt; HTTP-Anforderungen können an jeden beliebigen Server weitergeleitet werden, da der Server keinen bestimmten Zustand für einen Client aufrechterhalten muss. Dies erleichtert die Skalierung der Anzahl von Servern entsprechend der erwarteten Arbeitslast, bei der die Aufrechterhaltung einer dauerhaften Verbindung ressourcenintensiv wäre. Wenn es notwendig ist, mit einer Website in einer progressiven Weise zu interagieren, z. B. beim Online-Shopping, kann HTTP Cookies, serverseitige Sitzungen, URL-Rewriting oder versteckte Variablen verwenden, um zustandsabhängige Sitzungen zu ermöglichen Diese Umgehungen werden zustandsabhängige Funktionen genannt. Ein weiterer Vorteil der Zustandslosigkeit ist, dass die Menge der zu übertragenden Daten in den meisten Fällen minimiert wird.
Der gesamte TCP/IP-Stack ist nicht zustandslos. TCP auf der Transportschicht ist zustandsbehaftet, hält den Zustand einer HTTP-Sitzung aufrecht und stellt sicher, dass verlorene Datenpakete erneut übertragen werden können.
HTTP gilt im Allgemeinen als verbindungslos ("connectionless"), da die Verbindung sofort abgebrochen wird, nachdem der Client eine Verbindung zu einem Server hergestellt, eine Anfrage gesendet und eine Antwort erhalten hat. HTTP gilt auch deshalb als verbindungslos, weil die Netzwerkverbindungen auf der Transportschicht und nicht auf der Anwendungsschicht gesteuert werden. HTTP verwendet auf der Transportschicht TCP, das auf Verbindungen basiert.
Solange sowohl der Client als auch der Server wissen, wie bestimmte Dateninhalte, die durch den MIME-Typ in einem Header angegeben sind, zu behandeln sind, kann jede Art von Daten über HTTP gesendet werden. MIME steht für "Multipurpose Internet Mail Extensions".
HTTP wird im Web überall dort verwendet, wo Daten zwischen einem Client und einem Server übertragen werden müssen, z. B. bei APIs, Webdiensten und Browser-Anfragen.
HTTP wird in der Regel von Nutzern verwendet, die keine vertraulichen Informationen haben, bei denen sie befürchten müssen, dass sie gehackt werden, die kein SSL-Zertifikat erwerben möchten oder die die Komplexität der Pflege einer sicheren Website nicht wünschen.
Frühe Versionen von HTTP waren zustandslos, aber nicht sitzungslos. Eine HTTP-Sitzung besteht in der Regel aus drei Schritten, wobei die einzelnen Schritte in den verschiedenen Versionen unterschiedlich gehandhabt werden.
Zunächst baut der Client eine Verbindung zum Server auf. In den meisten Versionen von HTTP ist dies eine TCP-Verbindung, aber HTTP/3 verwendet UDP auf der Transportschicht.
Zweitens sendet der Client eine Anforderungsnachricht, um z. B. eine Webseite aufzurufen. Eine Anforderungsmethode in der Nachricht gibt die Aktion an, die der Server durchführen muss. Um beispielsweise eine Webseite anzuzeigen, verwendet der Client die GET-Methode .
Drittens verarbeitet der Server die Anfrage und sendet eine Antwortnachricht an den Client, z. B. den Inhalt der angeforderten Webseite, wenn die Anfrage erfolgreich war, und einen Statuscode.
In HTTP-Versionen vor HTTP/1.1 wurde die Verbindung nach Abschluss einer Anfrage standardmäßig geschlossen. Wenn der Client wollte, dass die Verbindung offen bleibt, musste er dies durch Aktivierung des Keep-Alive Connection Headers angeben. HTTP/1.1 und nachfolgende HTTP-Versionen erlauben es dem Client, zusätzliche Anforderungsnachrichten zu senden, und die Verbindung wird standardmäßig aufrechterhalten. Wenn ein Client also einen Fehlercode erhält, möchte er die Anfrage möglicherweise erneut stellen. Wenn der Client möchte, dass die Verbindung geschlossen wird, muss er dies mit dem Header Close Connection angeben.
Zwischen dem Client und dem Server stehen zahlreiche weitere Server, so genannte Proxyserver, die zusätzliche Funktionen wie die Verschlüsselung von Inhalten, den Cache und die Komprimierung von Daten, den Lastenausgleich, die Protokollierung und die Bereitstellung gemeinsamer Verbindungen für gleichzeitige Benutzer übernehmen.
HTTP-Nachrichten werden in einem MIME-ähnlichen Format ausgetauscht. MIME ist ein Standard für Internet-Mail, der es ermöglicht, das Format von Nachrichtenanforderungen zu erweitern, um andere Daten als reinen ASCII-Text zu unterstützen. MIME-ähnliche Header in HTTP haben eine ähnliche Funktion; sie ermöglichen es einem Client beispielsweise, die geeignete Anwendung auszuwählen, um andere Dateien als Text zu öffnen, z. B. Video, Bilder, ausführbare Dateien, Audio usw.
HTTP-Anforderungen und HTTP-Antworten verwenden das gleiche Nachrichtenformat. Nachrichten bestehen aus einer Startzeile (entweder eine Anfragezeile im Falle einer Anforderungsnachricht oder eine Statuszeile im Falle einer Antwortnachricht), einem oder mehreren optionalen Header-Feldern, einer Leerzeile, die anzeigt, dass es keine weiteren Header-Felder gibt, und einem optionalen Nachrichtentext.
Die Startzeile enthält die Protokollversion und einige Informationen über die Art der Anfrage (im Falle einer Anforderungsnachricht) oder den Erfolg oder Misserfolg der Anfrage (im Falle einer Antwortnachricht).
HTTP-Header ermöglichen die Aufnahme zusätzlicher Informationen über die Anfrage oder die Antwort, wie z. B. die Anfragemethode im Falle von Anfragemeldungen und die Länge des zurückgegebenen Inhalts im Falle von Antwortmeldungen.
Der optionale Nachrichtentext einer Anfrage kann die Informationen enthalten, die auf einen Server hochgeladen oder von diesem gelöscht werden müssen. Der optionale Nachrichtentext in einer Antwort kann den vom Client angeforderten Inhalt enthalten.
Die Verwendung von Headern macht HTTP als Client flexibel und erweiterbar, und ein Server kann neue, für eine Transaktion relevante Header erstellen, solange sich beide auf das Format einigen.
Einige HTTP-Header sind spezifisch für Anfrage- oder Antwortnachrichten, z. B. ist der Accept-Language-Header spezifisch für Anforderungsnachrichten. Einige Header können jedoch sowohl in Anfragen als auch in Antworten erscheinen. Der Header Content-Type, der als Repräsentationsheader kategorisiert ist, kann beispielsweise in Anfragen oder Antworten enthalten sein. Im ersten Fall gibt er an, welche Art von Inhalt der Kunde wünscht. Im letzteren Fall gibt er an, welche Art von Inhalt der Server zurückgibt.
Anforderungs-Header können zusätzliche Informationen über den Client und die Ressource enthalten. Der Uniform Resource Identifier (URI) ist zum Beispiel die Ressource, auf die die Methode reagieren muss, um Informationen von einer bestimmten Website zu erhalten. HTTP-Anforderungs-Header können auch Informationen darüber enthalten, welche Daten in den Cache gestellt werden sollen, allgemeine Verbindungsinformationen, Authentifizierungsdetails, Datum und Uhrzeit, Informationen zur Übertragungskodierung, in welchem Format Informationen zur Übertragung von Inhalten verwendet werden können, usw.
Accept-Anforderungs-Header - wie Accept-language und Accept-encoding - und einige ergänzende Repräsentations-Header - wie Content-Language und Content-Encoding - ermöglichen die Inhaltsverhandlungsfunktion von HTTP. Die Accept-Header geben die Präferenzen des Clients an, während die komplementären Representation-Header in der Antwort angeben, was der Server tatsächlich zurückgegeben hat.
Antwort-Header können zusätzliche Informationen über den Server und die Ressource enthalten. Sie können auch Cookies, die Länge des zurückgegebenen Inhalts, die Art des Inhalts, das Datum der letzten Änderung usw. enthalten.
Es gibt spezielle Header für zahlreiche HTTP-Funktionen wie Authentifizierung, Verbindungsarten, Speicherung von Cookies, Herunterladen von Dateien, Proxy-Management, Sicherheit, Übertragungskodierung usw.
HTTP ist ein Anfrage-Antwort-Modell für die Netzwerkkommunikation. Sein Gegenstück ist das Publish-Subscribe-Modell, bei dem ein Server (auch Broker genannt) Daten empfängt und verteilt, während der Client entweder Daten auf dem Server veröffentlicht, um sie zu aktualisieren, oder den Server abonniert, um Informationen zu erhalten. Beim Publish-Subscribe-Modell werden die Daten automatisch ausgetauscht, aber nur, wenn sie sich ändern oder wenn es sich um neue Informationen handelt. MQTT ist ein Beispiel für ein Transportprotokoll, das Publish-Subscribe verwendet.
Web Real-Time Communication (WebRTC) wird für Peer-to-Peer-Verbindungen (P2P) verwendet, die die einfache gemeinsame Nutzung von Anwendungsdaten und Mediendateien wie Audio und Video ermöglichen. Facebook Messenger ist ein Beispiel für eine Anwendung, die WebRTC verwendet.
QUIC verwendet TCP, ist aber auf UDP aufgebaut. QUIC wurde entwickelt, um die Latenzzeit bei Internetdatenübertragungen zu verringern und einige HTTP/2-Probleme zu lösen. Google Chrome ist ein Beispiel für eine Anwendung, die QUIC verwendet.
Das InterPlanetary File System (IPFS) ist eine neuere Alternative zu HTTP, die über eine verteilte P2P-Architektur verfügt und die Wahl zwischen TCP-, QUIC- und WebRTC-Verbindungen lässt. Mit seiner verteilten Architektur wurde es entwickelt, um die Probleme von Serverausfällen zu lösen, die bei zentralisierten Netzwerkkommunikationsprotokollmodellen wie HTTP häufig auftreten.
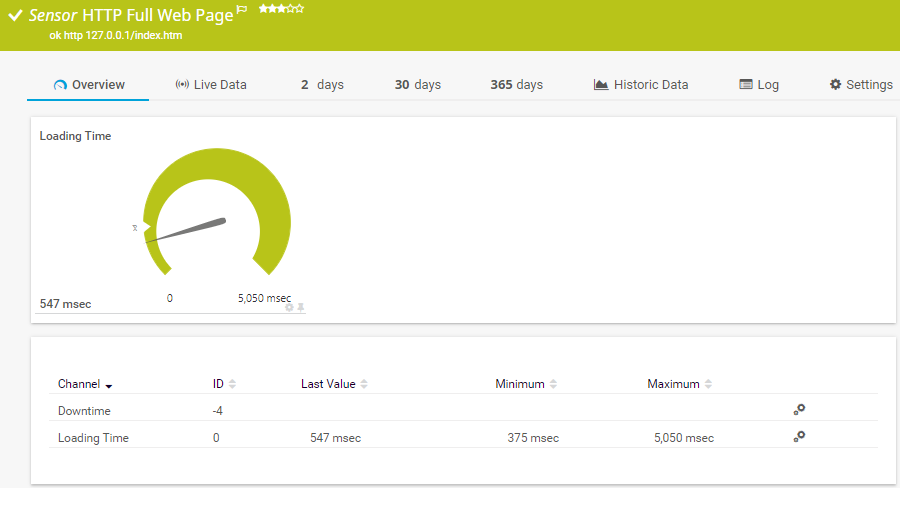
Sensor HTTP Vollständige Web-Seite
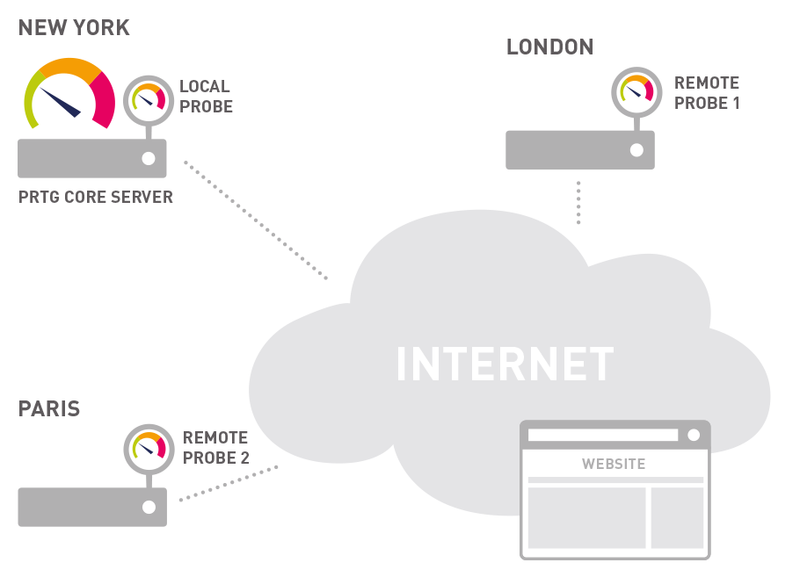
Cloud HTTP Monitoring
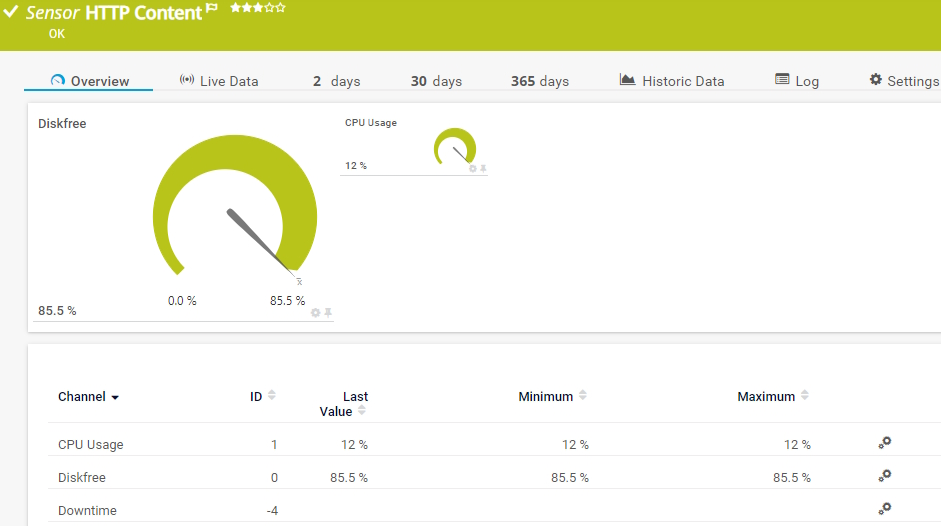
Sensor HTTP Inhalt




Hypertext Transfer Protocol Secure (HTTPS) ist im Grunde HTTP mit Verschlüsselung; es "verpackt" HTTP-Nachrichten in ein verschlüsseltes Format. HTTPS verwendet Transport Layer Security (TLS), um HTTP-Anforderungen und -Antworten zu verschlüsseln.
HTTP und HTTPS verwenden unterschiedliche Ports. Üblicherweise verwendet HTTP den Port 80 und HTTPS den Port 443, obwohl theoretisch jeder Port verwendet werden kann, außer denen, die für bestimmte Dienste reserviert sind.
Der Hauptvorteil der Verwendung von HTTPS ist die verbesserte Sicherheit. Für Websites, auf denen keine vertraulichen Informationen übertragen werden, könnte HTTP eine akzeptable Option sein, die weniger komplex in der Einrichtung und Wartung ist. Darüber hinaus kündigte Google 2014 an, HTTPS als leichtes Ranking-Signal zu verwenden, um Unternehmen zu ermutigen, von HTTP auf HTTPS zu wechseln.
Die Verwendung von HTTPS anstelle von HTTP hat einige subtile und in der Praxis geringfügige Nachteile. Erstens kann es bei der Übertragung von Daten zu einem gewissen Mehraufwand kommen, da zunächst ein Handshaking durchgeführt werden muss. Zweitens kann der Prozess der Erzeugung von Verschlüsselungsschlüsseln den Server von anderen Aufgaben abhalten. Drittens können einige Inhalte nicht lokal gecached werden, da die Daten verschlüsselt sind.
Standardmäßig ist HTTP/3 nur mit HTTPS verfügbar.
Benachrichtigungen in Echtzeit bedeuten eine schnellere Fehlerbehebung, sodass Sie handeln können, bevor ernstere Probleme auftreten.
TCP ist zuverlässiger, aber langsamer als UDP. Kombiniert man jedoch UDP mit QUIC, so erhält man mit HTTP/3 eine schnelle und zuverlässige Paketübertragung. HTTP/3 befindet sich noch in den Kinderschuhen. Bis Anfang 2021 wurde es von beliebten Anwendungen wie Google, WhatsApp, YouTube und Facebook unterstützt, nicht aber von ebenso beliebten Anwendungen wie Uber oder Twitter.
HTTP/3 ist noch ein RFC-Entwurf, wird aber laut Wikipedia von fast 75 Prozent der Webbrowser und laut W3Techs von 21 Prozent der Top 10 Millionen Websites unterstützt, für die W3Techs Nutzungsdaten bereitstellt.
Die Kommerzialisierung des Internets hat zu einem erhöhten Bedarf an Netzwerkanalysen und Monitoring in Echtzeit geführt, um Unternehmen eine maximale Betriebszeit zu ermöglichen. Das Monitoring und die Analyse von Paketen - auch Packet Sniffing genannt - ist der Schlüssel zur Analyse, welche Pakete wann und warum verloren gehen, um eine hohe und gleichbleibende Leistung zu gewährleisten.
Das PTRG Packet-Sniffing-Tool überwacht und analysiert jedes Paket in Ihrem Netzwerk, um die genutzte Bandbreite, Bandbreitenfresser und potenzielle Sicherheitslücken zu identifizieren. Der Packet Sniffer überwacht den gesamten HTTP-, HTTPS-, UDP- und TCP-Verkehr sowie anderen Mail-, File-Transfer-, Remote-Control- und Infrastrukturverkehr.
Mit dem PTRG Web-Sensoren-Tool können Sie Webserver überwachen, die HTTP verwenden, um sicherzustellen, dass die Webseiten immer erreichbar sind.

