
HTTP é a sigla de Hypertext Transfer Protocol (Protocolo de Transferência de Hipertexto). É um protocolo de solicitação-resposta na camada de aplicativos para a Web. O HTTP tem uma arquitetura cliente-servidor que permite a transferência confiável de recursos entre um servidor de aplicativos da Web e um agente de usuário (UA), como um navegador da Web. Os UAs incluem rastreadores da Web, aplicativos móveis e outros softwares usados para acessar recursos da Web.
O HTTP foi projetado para permitir a comunicação fácil entre dispositivos e aplicativos na Web. O TI define como as solicitações de conteúdo são formatadas e transmitidas e como as respostas são construídas. O HTTP transmite conteúdo como texto, imagens, áudio e vídeo usando um conjunto de protocolos chamado TCP/IP (Transmission Control Protocol/Internet Protocol).
À medida que o HTTP evoluiu, cada versão adicionou novos recursos e cada uma delas executa alguns processos, como o gerenciamento de conexões, de forma diferente.
Tim Berners-Lee, considerado o fundador da Web, escreveu a primeira versão do HTTP. As especificações para HTTP, Hypertext Markup Language (HTML) e Uniform Resource Identifier (URI) foram escritas entre 1989 e 1990. O primeiro servidor da Web entrou em operação em 1991.
Um protocolo de Internet é um conjunto de regras que define como os dispositivos em uma rede de Internet se comunicam. Esse conjunto de regras baseia-se em padrões comuns criados por solicitações de comentários (RFCs). As RFCs são os blocos de construção dos padrões usados na comunicação de rede na Internet. As RFCs são gerenciadas pela IETF (Internet Engineering Task Force), o principal órgão de definição de padrões para o funcionamento da Internet. Exemplos de protocolos de rede comuns incluem HTTP, TCP, IPS, FTP e Secure Shell (SSH).
Os protocolos de rede podem ser mais detalhados. O modelo OSI (Open Systems Interconnection) é uma estrutura conceitual que descreve as funções de um sistema de computação. O TI consiste em sete camadas: física, de link de dados, de rede, de transporte, de sessão, de apresentação e de aplicativo. Os dados em cada camada são gerenciados por diferentes protocolos. O HTTP é um protocolo da camada 7 (aplicativo), que não deve ser confundido com a camada de rede do modelo OSI.
Os dados na Internet são gerenciados e transmitidos por uma pilha de protocolos de rede que são chamados coletivamente de TCP/IP. Cada camada da pilha pode ser mapeada para camadas no modelo OSI e cada uma tem uma função diferente. O HTTP faz parte da camada de aplicativos e permite que diferentes aplicativos se comuniquem entre si. A TI usa o TCP para estabelecer sessões entre um cliente e um servidor. O TCP faz parte da camada de transporte da pilha. A TI divide as mensagens em pacotes de dados em sua origem, que são remontados em seu destino. IP no acrônimo TCP/IP é o protocolo que direciona os pacotes de dados para um computador específico por meio de um endereço IP. O IPS faz parte da camada de rede da pilha.
Teoricamente, o HTTP poderia usar um protocolo de camada de transporte alternativo ao TCP, como o UDP, mas o HTTP quase sempre usa o TCP, que é baseado em conexão e mais confiável que o UDP. TI é preferido por aplicativos em que os dados devem ser confiáveis, relevantes e completos, por exemplo, uma notícia. O UDP é um protocolo sem conexão e não pode retransmitir pacotes de dados perdidos. No entanto, o UDP é mais rápido que o TCP e é frequentemente usado em aplicativos como videoconferência e streaming, em que pequenos soluços de transferência são quase imperceptíveis. Entretanto, a versão preliminar mais recente do HTTP, HTTP/3, aborda alguns dos problemas do TCP e do UDP, combinando recursos de dois protocolos: HTTP/2 e QUIC over UDP. O HTTP/3 também é chamado de HTTP-over-QUIC.
O QUIC é um protocolo de rede que funciona como uma alternativa a uma combinação de TCP, TLS (Transport Layer Security) e HTTP/2. Ele é implementado sobre o UDP. O QUIC transporta o tráfego HTTP/3 por UDP com mais rapidez e eficiência do que as versões mais antigas do HTTP que usam TCP. O QUIC reduz a latência da conexão, aprimora o controle de congestionamento, permite a multiplexação sem bloqueio de cabeça de linha, possibilita a correção de erros de encaminhamento e permite a migração de conexão. O QUIC é totalmente criptografado com TLS 1.3 por padrão. O UDP é um protocolo sem conexão, portanto, uma das principais funções do QUIC é garantir a confiabilidade da conexão, permitindo a retransmissão de pacotes, por exemplo.
A primeira versão do HTTP incluía apenas o método de solicitação GET e não tinha cabeçalhos, metadados como tipo de conteúdo ou códigos de status. Como o HTTP/09 não usava cabeçalhos, somente páginas HTML (hipertexto) podiam ser retornadas ao cliente. Após o recebimento de uma resposta do servidor, o cliente fechava imediatamente a conexão. O HTTP/09 está, em sua maior parte, obsoleto, mas alguns servidores da Web populares, como o nginx, ainda o suportam.
O HTTP/1.0 suportava os métodos GET e POST e adicionava informações de versão e códigos de status. Foram introduzidos cabeçalhos que permitiam a especificação de um tipo de conteúdo para que arquivos diferentes de HTML pudessem ser transmitidos. Após o recebimento de uma resposta do servidor, o cliente fechava imediatamente a conexão. A introdução de cabeçalhos no HTTP/1.0 tornou o HTTP muito extensível.
Quando uma solicitação de uma página da Web é feita, a página deve ser renderizada em várias partes, por exemplo, conteúdo de texto e outros conteúdos, como imagens ou vídeos. Os arquivos de imagem, vídeo e áudio têm seus próprios URLs, e cada arquivo deve ser solicitado separadamente. No HTTP/1, isso significava que várias solicitações individuais tinham de ser feitas ao servidor e várias conexões tinham de ser iniciadas. O HTTP/1.1 introduziu conexões persistentes e pipelining. Uma conexão persistente não é fechada por padrão depois que uma solicitação é feita. Pipelining significa que solicitações sucessivas em uma transação podem ser feitas por um cliente sem esperar por uma resposta do servidor. As conexões persistentes e o pipelining permitiram que o hipertexto e outros arquivos, como imagens, fossem enviados sucessivamente do servidor para o cliente em uma única conexão com latência reduzida. O HTTP/1.1 também permitia métodos adicionais, como DELETE, PUT e TRACE. Essa versão introduziu o suporte a cache, cookies de cliente, transferências codificadas e negociação de conteúdo. A negociação de conteúdo permitiu que o servidor e o cliente selecionassem o conteúdo mais adequado a ser trocado em termos de idioma, codificação ou tipo de conteúdo. O HTTP/1.1 também tornou a padronização do HTTP mais consistente e atualmente é a versão mais usada do HTTP.
Baseado no SPDY, o HTTP/2 é um protocolo de comunicação obsoleto desenvolvido pelo Google para reduzir a latência de carregamento de páginas da Web e melhorar a segurança. O TI foi projetado para melhorar o desempenho da Web e cortar custos, pois o HTTP/1.1 era caro em termos de uso de recursos da CPU. O HTTP/2 introduziu a multiplexação avançada, que é a capacidade de transmitir com eficiência dados de vários recursos em uma única sessão usando quadros HTTP e fluxos HTTP. Esse recurso foi introduzido para resolver os problemas de bloqueio de cabeçalho de linha do HTTP/1.1 e para permitir a comunicação paralela em uma única conexão TCP. O bloqueio de HTTP head-of-line refere-se ao cenário em que solicitações sucessivas em um fluxo podem ser bloqueadas se houver um problema com a solicitação atual na fila ou se ela ainda não tiver sido concluída.
Enquanto as solicitações e respostas HTTP/1.1 estão em formato de texto, os quadros HTTP/2 usam o formato binário.
Os quadros binários do HTTP/2 dividem uma solicitação de mensagem em unidades lógicas separadas, como quadros de cabeçalho e quadros de dados, cada um dos quais é codificado em binário e compartilha um ID de fluxo HTTP comum. Um fluxo HTTP/2 é uma solicitação lógica única, bidirecional, que compreende vários quadros. No HTTP/2, vários fluxos podem ser enviados (multiplexados) em uma única conexão TCP para um servidor que, em seguida, mapeia os quadros por sua ID de fluxo e os remonta em mensagens de solicitação HTTP/2 completas de acordo com uma prioridade de mensagem predeterminada. A multiplexação permite que várias solicitações ocorram em uma conexão e o servidor também pode enviar várias respostas ao cliente da mesma forma. Esse recurso evita o bloqueio de head-of-line na camada do aplicativo e melhora o desempenho.
O HTTP/2 também introduziu um melhor tratamento de erros e controle de fluxo, além do server push. O push de servidor significa que o servidor pode enviar dados ao cliente que não foram solicitados explicitamente, por exemplo, recursos que o servidor intui que podem ser necessários ao cliente. O TI primeiro notificará o cliente sobre o que pretende enviar e o cliente poderá recusar.
De acordo com a W3Techs o HTTP/2 é usado por cerca de 46% dos sites. O TI não é compatível com as versões anteriores do HTTP.
A terceira versão do HTTP, HTTP/3, foi projetada para melhorar o desempenho do HTTP/2 e resolver alguns problemas do HTTP/2. O HTTP/3 usa UDP na camada de transporte em vez de TCP. O bloqueio de cabeça de linha na camada TCP no HTTP/2 é resolvido pelo uso do UDP. O bloqueio de cabeça de linha do TCP refere-se ao cenário em que, se um pacote for perdido, uma mensagem é bloqueada até que o pacote possa ser recuperado. O HTTP/3 permite conexões mais rápidas, pois não depende de endereços de TI. O TI usa IDs de conexão para que os downloads sejam consistentes mesmo quando há uma mudança na rede. Ao contrário do TCP, o UDP não exige que uma transferência de dados seja confirmada antes que a próxima solicitação seja transmitida. As conexões também são mais rápidas porque menos pacotes de dados precisam ser enviados em fluxos paralelos. Para estabelecer uma conexão, o TCP usa um handshake de três vias. O UDP cria uma conexão em uma ida e volta. Como o TLS 1.3 está integrado ao HTTP/3, ele só oferece suporte a conexões criptografadas (HTTPS).
Os alertas personalizados e a visualização de dados permitem que você identifique e evite rapidamente problemas de saúde e desempenho da rede.
Os cabeçalhos tornam o HTTP extensível, pois o cliente e o servidor podem concordar em adicionar novos nomes de campos e informações para atender às suas necessidades.
Embora seja possível, um servidor HTTP não é obrigado a armazenar nenhuma informação entre as solicitações. Esse recurso tornou as primeiras versões do HTTP sem estado. As solicitações nas versões anteriores ao HTTP/2 eram feitas de forma independente, sem nenhum conhecimento do que havia acontecido nas solicitações anteriores. O HTTP foi projetado como um modelo sem estado principalmente para fins de escalabilidade; as solicitações HTTP podem ser roteadas para qualquer servidor porque o servidor não precisa manter um estado específico para um cliente. Isso facilita o dimensionamento do número de servidores para corresponder à carga de trabalho esperada, em que a manutenção de uma conexão persistente exigiria muitos recursos. Quando é necessário interagir com um site de forma progressiva, por exemplo, ao fazer compras on-line, o HTTP pode usar cookies, sessões do lado do servidor, reescrita de URL ou variáveis ocultas para permitir sessões com estado. Outra vantagem da ausência de estado é que a quantidade de dados que precisa ser transferida na maioria dos casos é minimizada.
A pilha TCP/IP completa não é sem estado. O TCP na camada de transporte tem estado, mantendo o estado de uma sessão HTTP e garantindo que os pacotes de dados perdidos possam ser retransmitidos.
Em geral, o HTTP é considerado sem conexão porque, depois que o cliente estabelece uma conexão com um servidor, envia uma solicitação e recebe uma resposta, a conexão é imediatamente interrompida. O HTTP também é considerado sem conexão porque as conexões de rede são controladas na camada de transporte, não na camada do aplicativo. O HTTP usa o TCP, que é baseado em conexão, na camada de transporte.
Desde que o cliente e o servidor saibam como lidar com o conteúdo de dados específicos, conforme especificado pelo tipo MIME em um cabeçalho, qualquer tipo de dados pode ser enviado via HTTP. MIME significa Multipurpose Internet Mail Extensions (Extensões de Correio da Internet para Fins Múltiplos).
O HTTP é usado na Web sempre que os dados precisam ser transferidos entre um cliente e um servidor, por exemplo, APIs, serviços da Web e solicitações do navegador.
O HTTP geralmente é usado por usuários que não têm informações confidenciais com as quais precisam se preocupar para não serem invadidas, que não desejam comprar um certificado SSL ou que não querem a complexidade de manter um site seguro.
As primeiras versões do HTTP eram sem estado, mas não sem sessão. Normalmente, uma sessão HTTP tem três etapas, com alguma variação na forma como as etapas são tratadas em diferentes versões.
Primeiro, o cliente estabelece uma conexão com o servidor. Na maioria das versões do HTTP, essa é uma conexão TCP, mas o HTTP/3 usa UDP na camada de transporte.
Em segundo lugar, o cliente envia uma mensagem de solicitação para exibir uma página da Web, por exemplo. Um método de solicitação na mensagem especifica a ação que o servidor precisa executar. Por exemplo, para exibir uma página da Web, o cliente usará o método GET .
Em terceiro lugar, o servidor processa a solicitação e retorna uma mensagem de resposta ao cliente, por exemplo, o conteúdo da página da Web solicitada, se a solicitação foi bem-sucedida, e um código de status.
Nas versões HTTP anteriores à HTTP/1.1, a conexão era fechada após a conclusão de uma solicitação por padrão. Se o cliente quisesse que a conexão fosse mantida aberta, teria de especificar isso ativando o cabeçalho Keep-Alive Connection. O HTTP/1.1 e as versões subsequentes do HTTP permitem que o cliente envie mensagens de solicitação adicionais e a conexão é mantida ativa por padrão. Portanto, se um cliente receber um código de erro, ele poderá tentar novamente a solicitação. Se o cliente quiser que a conexão seja fechada, isso deve ser especificado com o cabeçalho Close Connection.
Entre o cliente e o servidor há vários outros servidores chamados proxies, que são intermediários que executam funções adicionais como criptografia de conteúdo, cache e compactação de dados, balanceamento de carga, logs e fornecimento de conexões compartilhadas para usuários simultâneos.
As mensagens HTTP são trocadas em um formato semelhante ao MIME. O MIME é um padrão para correio eletrônico da Internet que permite que o formato das solicitações de mensagens seja estendido para suportar dados que não sejam texto ASCII simples. Os cabeçalhos do tipo MIME no HTTP têm uma função semelhante; por exemplo, eles permitem que um cliente selecione o aplicativo apropriado para abrir arquivos que não sejam de texto, como vídeo, imagens, executáveis, áudio etc.
As solicitações HTTP e as respostas HTTP usam o mesmo formato de mensagem. As mensagens consistem em uma linha inicial (uma linha de solicitação, no caso de uma mensagem de solicitação, ou uma linha de status, no caso de uma mensagem de resposta), um ou mais campos de cabeçalho opcionais, uma linha vazia que indica que não há mais campos de cabeçalho e um corpo de mensagem opcional.
A linha inicial inclui a versão do protocolo e algumas informações sobre o tipo de solicitação, no caso de uma mensagem de solicitação, ou o sucesso ou a falha da solicitação, no caso de uma mensagem de resposta.
Os cabeçalhos HTTP permitem a inclusão de informações adicionais sobre a solicitação ou a resposta, como o método de solicitação, no caso de mensagens de solicitação, e o tamanho do conteúdo retornado, no caso de mensagens de resposta.
O corpo da mensagem opcional em uma solicitação pode incluir as informações que precisam ser carregadas ou excluídas de um servidor. O corpo da mensagem opcional em uma resposta pode incluir o conteúdo solicitado pelo cliente.
O uso de cabeçalhos é o que torna o HTTP flexível e extensível como cliente, e um servidor pode criar novos cabeçalhos relevantes para uma transação, desde que ambos concordem com o formato.
Alguns cabeçalhos HTTP são específicos para mensagens de solicitação ou resposta, por exemplo, o cabeçalho Accept-Language é específico para mensagens de solicitação. Entretanto, alguns cabeçalhos podem aparecer tanto em solicitações quanto em respostas. Por exemplo, o cabeçalho Content-Type, classificado como um cabeçalho de representação, pode ser incluído em mensagens de solicitação ou de resposta. No primeiro caso, ele especifica o tipo de conteúdo que o cliente deseja. No segundo, ele especifica o tipo de conteúdo que o servidor está retornando.
Os cabeçalhos de solicitação podem incluir informações adicionais sobre o cliente e o recurso. Por exemplo, o URI (Uniform Resource Identifier, Identificador Uniforme de Recurso) é o recurso sobre o qual o método precisa agir para obter informações de um site específico, por exemplo. Os cabeçalhos de solicitação HTTP também podem especificar informações sobre quais dados devem ser armazenados em cache, informações gerais de conexão, detalhes de autenticação, data e hora, informações de codificação de transferência, em que formato as informações podem ser usadas para transferir conteúdo etc.
Os cabeçalhos de solicitaçãoAccept - como Accept-language e Accept-encoding - e alguns cabeçalhos de representação complementares - como Content-Language e Content-Encoding - permitem o recurso de negociação de conteúdo do HTTP. Os cabeçalhos Accept especificam as preferências do cliente e os cabeçalhos de representação complementar na resposta especificam o que o servidor realmente retornou.
Os cabeçalhos de resposta podem incluir informações adicionais sobre o servidor e o recurso. Eles também podem especificar quaisquer cookies, o tamanho do conteúdo retornado, o tipo de conteúdo, quando o conteúdo foi modificado pela última vez etc.
Há cabeçalhos especiais para várias funções HTTP, como autenticação, tipos de conexão, armazenamento de cookies, download de arquivos, gerenciamento de proxy, segurança, codificação de transferência etc.
O HTTP é um modelo de solicitação-resposta para comunicação de rede. Sua contraparte é o modelo de publicação-assinatura, no qual um servidor (também chamado de corretor) recebe e distribui dados, enquanto o cliente publica dados no servidor para atualizá-los ou se inscreve no servidor para receber informações. No modelo de publicação e assinatura, os dados são automaticamente trocados, mas somente quando são alterados ou quando as informações são novas. O MQTT é um exemplo de um protocolo de transporte que usa publicação-assinatura.
O Web Real-Time Communication (WebRTC) é usado para realizar conexões peer-to-peer (P2P), que permitem o fácil compartilhamento de dados de aplicativos e arquivos de mídia, como áudio e vídeo. O Facebook Messenger é um exemplo de aplicativo que usa WebRTC.
O QUIC usa TCP, mas é construído com base no UDP. O QUIC foi projetado para reduzir a latência nas transferências de dados da Internet e para resolver alguns problemas do HTTP/2. O Google Chrome é um exemplo de aplicativo que usa QUIC.
O IPFS (InterPlanetary File System) é uma alternativa recente ao HTTP que tem uma arquitetura P2P distribuída e permite a escolha de conexões TCP, QUIC ou WebRTC. Com sua arquitetura distribuída, ele foi projetado para resolver problemas de falha do servidor que são comuns aos modelos de protocolo de comunicação de rede centralizados, como o HTTP.
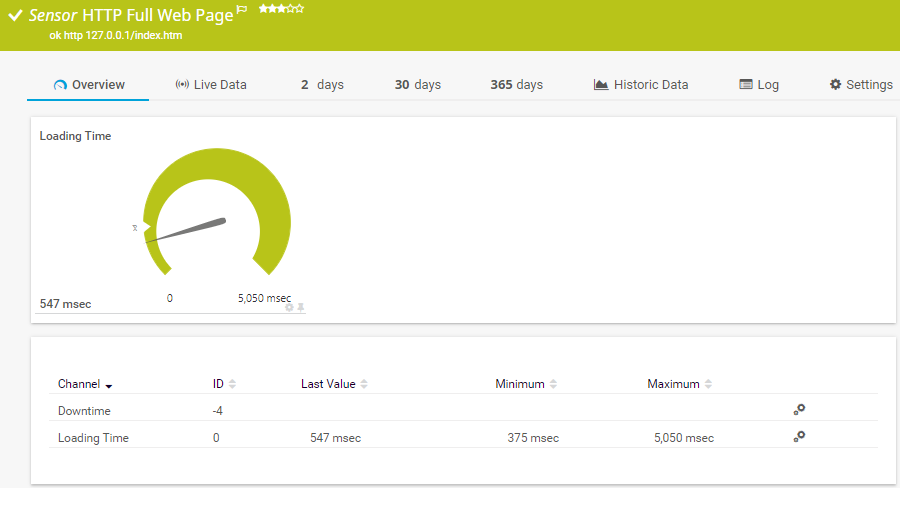
Página da Web completa do sensor HTTP
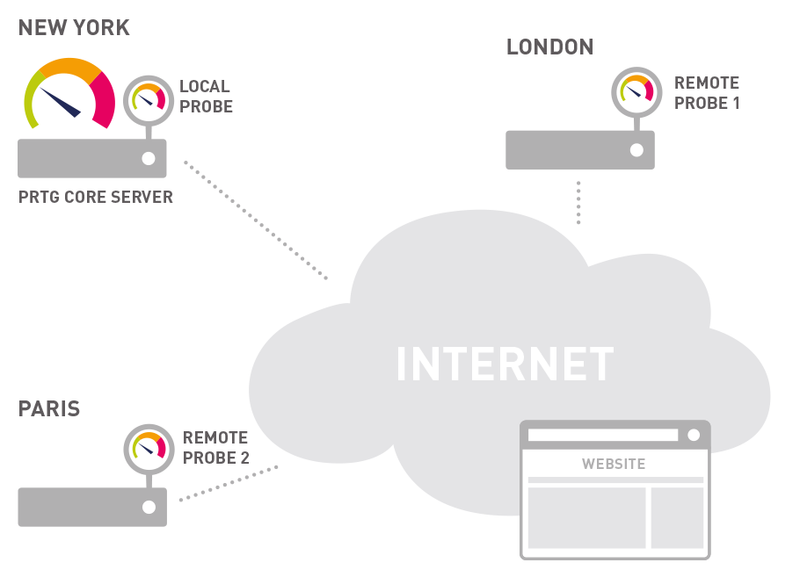
Monitoramento de HTTP em nuvem
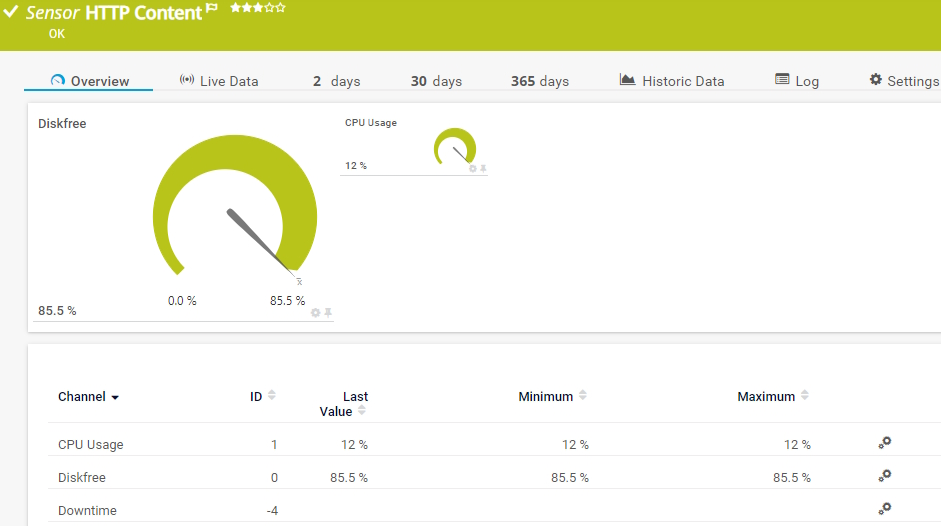
Conteúdo HTTP do sensor




O HTTPS (Hypertext Transfer Protocol Secure) é basicamente HTTP com criptografia; ele "envolve" as mensagens HTTP em um formato criptografado. O HTTPS usa o TLS (Transport Layer Security) para criptografar solicitações e respostas HTTP.
O HTTP e o HTTPS usam portas diferentes. Normalmente, o HTTP usa a porta 80 e o HTTPS usa a porta 443, embora, em teoria, qualquer porta possa ser usada, exceto aquelas reservadas para serviços específicos.
A principal vantagem de usar HTTPS é a segurança aprimorada. Para sites que não transferem informações confidenciais, o HTTP pode ser uma opção aceitável e menos complexa de configurar e manter. Além disso, em 2014, o Google anunciou que usaria o HTTPS como um sinal de classificação leve para incentivar as empresas a mudar de HTTP para HTTPS.
Há algumas desvantagens sutis e, na prática, menores no uso de HTTPS em vez de HTTP. Em primeiro lugar, pode haver uma sobrecarga extra na transferência de dados, pois é necessário fazer um handshaking primeiro. Segundo, o processo de geração de chaves de criptografia pode impedir que o servidor execute outras tarefas. Terceiro, alguns conteúdos não podem ser armazenados em cache localmente porque os dados são criptografados.
Por padrão, o HTTP/3 só está disponível com HTTPS.
As notificações em tempo real significam uma solução de problemas mais rápida para que você possa agir antes que ocorram problemas mais sérios.
O TCP é mais confiável, mas é mais lento que o UDP. Entretanto, quando o UDP é combinado com o QUIC, o resultado é uma transmissão de pacotes rápida e confiável usando HTTP/3. O HTTP/3 ainda está em sua infância. No início de 2021, ele havia sido habilitado por aplicativos populares como Google, WhatsApp, YouTube e Facebook, mas não por aplicativos igualmente populares como Uber ou Twitter.
O HTTP/3 ainda é um rascunho de RFC, mas é suportado, de acordo com a Wikipedia, por quase 75% dos navegadores da Web e, de acordo com a W3Techs, 21% dos 10 principais milhões de sites para os quais a W3Techs fornece dados de uso.
A comercialização da Internet resultou em uma maior necessidade de análise e monitoramento da rede em tempo real para proporcionar às organizações o máximo de tempo de atividade. O monitoramento e a análise de pacotes - chamados de packet sniffing - são essenciais para analisar quais pacotes são perdidos, quando e por quê, a fim de manter um desempenho alto e consistente.
A ferramenta de monitoramento de pacotes do PTRG monitora e analisa cada pacote em sua rede para identificar a largura de banda usada, os problemas de largura de banda e as possíveis brechas de segurança. O sniffer de pacotes monitora todo o tráfego HTTP, HTTPS, UDP e TCP, bem como outros e-mails, transferência de arquivos, controle remoto e tráfego de infraestrutura.
A ferramenta de monitoramento da Web PTRG permite monitorar servidores da Web usando HTTP para garantir que as páginas da Web estejam sempre acessíveis.

