
HTTP signifie Hypertext Transfer Protocol (protocole de transfert hypertexte). Il s'agit d'un protocole demande-réponse de la couche application pour le web. HTTP possède une architecture client-serveur qui permet le transfert fiable de ressources entre un serveur d'application web et un agent utilisateur (UA) tel qu'un navigateur web. Les UA comprennent les robots d'indexation, les applications mobiles et d'autres logiciels utilisés pour accéder aux ressources web.
Le protocole HTTP a été conçu pour permettre une communication facile entre les appareils et les applications sur le web. Il définit la manière dont les demandes de contenu sont formatées et transmises, ainsi que la manière dont les réponses sont construites. HTTP transmet des contenus tels que du texte, des images, du son et de la vidéo à l'aide d'une suite de protocoles appelée Transmission Control Protocol/Internet Protocol (TCP/IP).
Au fil de l'évolution du HTTP, chaque version a ajouté de nouvelles fonctionnalités et exécute différemment certains processus, comme la gestion des connexions.
Tim Berners-Lee, considéré comme le fondateur du web, a écrit la première version de HTTP. Les spécifications de HTTP, du langage de balisage hypertexte (HTML) et de l'identificateur de ressources uniformes (URI) ont été rédigées entre 1989 et 1990. Le premier serveur web a été mis en service en 1991.
Un protocole internet est un ensemble de règles qui définit la manière dont les appareils d'un réseau internet communiquent. Cet ensemble de règles est basé sur des normes communes créées par des demandes de commentaires (RFC). Les RFC sont les builds des normes utilisées dans la communication réseau sur l'internet. Les RFC sont gérés par l'IETF (Internet Engineering Task Force), le principal organisme de normalisation du fonctionnement de l'internet. Parmi les exemples de protocoles réseau courants, citons HTTP, TCP, IP, FTP et Secure Shell (SSH).
Les protocoles de réseau peuvent être décomposés davantage. Le modèle OSI (Open Systems Interconnection) est un cadre conceptuel qui décrit les fonctions d'un système informatique. IT se compose de sept couches : physique, liaison de données, réseau, transport, session, présentation et application. Les données de chaque couche sont gérées par différents protocoles. HTTP est un protocole de la couche 7 (application), à ne pas confondre avec la couche réseau du modèle OSI.
Les données sur Internet sont gérées et transmises par une pile de protocoles de réseau qui sont collectivement appelés TCP/IP. Chaque couche de la pile peut être mise en correspondance avec les couches du modèle OSI et chacune a une fonction différente. HTTP fait partie de la couche application et permet à différentes applications de communiquer entre elles. Il utilise TCP pour établir des sessions entre un client et un serveur. TCP fait partie de la couche transport de la pile. Il divise les messages en paquets de données à leur source, qui sont ensuite réassemblés à leur destination. IPS, dans l'acronyme TCP/IP, est le protocole qui dirige les paquets de données vers un ordinateur spécifique par l'intermédiaire d'une adresse IP. IPS fait partie de la couche réseau de la pile.
En théorie, HTTP pourrait utiliser un autre protocole de couche de transport que TCP, comme UDP, mais HTTP utilise presque toujours TCP, qui est basé sur une connexion et plus fiable qu'UDP. Il est privilégié par les applications où les données doivent être fiables, pertinentes et complètes, par exemple un article d'actualité. UDP est un protocole sans connexion et ne peut pas retransmettre les paquets de données perdus. Cependant, l'UDP est plus rapide que le TCP et est souvent utilisé dans des applications telles que la vidéoconférence et la diffusion en continu, où les petits problèmes de transfert sont à peine perceptibles. La version préliminaire la plus récente de HTTP, HTTP/3, aborde toutefois certains des problèmes rencontrés par TCP et UDP, en combinant les caractéristiques de deux protocoles : HTTP/2 et QUIC sur UDP. HTTP/3 est également appelé HTTP-over-QUIC.
QUIC est un protocole réseau qui fonctionne comme une alternative à une combinaison de TCP, de Transport Layer Security (TLS) et de HTTP/2. Il est mis en œuvre au-dessus de l'UDP. QUIC transporte le trafic HTTP/3 sur UDP plus rapidement et plus efficacement que les anciennes versions HTTP qui utilisent TCP. QUIC réduit la latence de la connexion, améliore le contrôle de la congestion, permet le multiplexage sans blocage en tête de ligne, permet la correction d'erreur directe et permet la migration de la connexion. QUIC est entièrement chiffré avec TLS 1.3 par défaut. L'UDP étant un protocole sans connexion, l'une des principales fonctions de QUIC est d'assurer la fiabilité de la connexion en permettant, par exemple, la retransmission des paquets.
La première version de HTTP ne comprenait que la méthode de requête GET et n'avait pas d'en-têtes, de métadonnées telles que le type de contenu, ou de codes d'état. Comme HTTP/09 n'utilisait pas d'en-têtes, seules des pages HTML (hypertexte) pouvaient être renvoyées au client. Après avoir reçu une réponse du serveur, le client fermait immédiatement la connexion. L'HTTP/09 est, pour l'essentiel, obsolète, mais certains serveurs web populaires, comme nginx, le prennent encore en charge.
HTTP/1.0 prend en charge les méthodes GET et POST et ajoute des informations sur les versions et les codes d'état. Des en-têtes ont été introduits, ce qui a permis de spécifier un type de contenu afin que des fichiers autres que HTML puissent être transmis. Après avoir reçu une réponse du serveur, le client fermait immédiatement la connexion. L'introduction des en-têtes dans HTTP/1.0 a rendu HTTP très extensible.
Lorsqu'une page web est demandée, elle doit être rendue en plusieurs parties, par exemple du texte et d'autres contenus tels que des images ou des vidéos. Les fichiers image, vidéo et audio ont leur propre URL et chaque fichier doit être demandé séparément. Dans le protocole HTTP/1, cela signifiait que de multiples requêtes individuelles devaient être adressées au serveur et que de multiples connexions devaient être établies. Le protocole HTTP/1.1 a introduit les connexions persistantes et le pipelining. Une connexion persistante n'est pas fermée par défaut après une requête. Le pipelining signifie que des requêtes successives dans une transaction peuvent être effectuées par un client sans attendre une réponse du serveur. Les connexions persistantes et le pipelining ont permis l'envoi successif d'hypertextes et d'autres fichiers tels que des images du serveur au client sur une seule connexion avec un temps de latence réduit. HTTP/1.1 autorise également des méthodes supplémentaires, telles que DELETE, PUT et TRACE. Cette version a introduit la prise en charge du cache, les cookies clients, les transferts codés et la négociation de contenu. La négociation de contenu permet au serveur et au client de sélectionner le contenu le plus approprié à l'échange en termes de langue, de codage ou de type de contenu. HTTP/1.1 a également rendu la normalisation HTTP plus cohérente et est actuellement la version HTTP la plus utilisée.
Basé sur SPDY, HTTP/2 est un protocole de communication déprécié développé par Google pour réduire la latence de chargement des pages web et améliorer la sécurité. Il a été conçu pour améliorer les performances du web et réduire les coûts, car HTTP/1.1 était coûteux en termes d'utilisation des ressources du CPU. HTTP/2 a introduit le multiplexage avancé, c'est-à-dire la possibilité de diffuser efficacement des données provenant de plusieurs ressources au cours d'une même session à l'aide de trames HTTP et de flux HTTP. Cette fonctionnalité a été introduite pour résoudre les problèmes de blocage en tête de ligne du protocole HTTP/1.1 et pour permettre une communication parallèle sur une seule connexion TCP. Le blocage en tête de ligne HTTP fait référence au scénario dans lequel les requêtes successives d'un flux peuvent être bloquées en cas de problème avec la requête en cours dans la file d'attente ou si elle n'a pas encore été achevée.
Alors que les requêtes et réponses HTTP/1.1 sont au format texte, les trames HTTP/2 utilisent le format binaire.
Les trames binaires HTTP/2 décomposent une requête de message en unités logiques distinctes, comme les trames d'en-tête et les trames de données, chacune étant codée en binaire et partageant un identifiant de flux HTTP commun. Un flux HTTP/2 est une requête logique unique et bidirectionnelle qui comprend plusieurs trames. Dans HTTP/2, plusieurs flux peuvent être envoyés (multiplexés) sur une seule connexion TCP à un serveur qui cartographie ensuite les trames par leur ID de flux et les réassemble en messages de requête HTTP/2 complets en fonction d'une priorité de message prédéterminée. Le multiplexage permet d'effectuer plusieurs requêtes sur une seule connexion et le serveur peut également envoyer plusieurs réponses au client de la même manière. Cette fonctionnalité permet d'éviter le blocage en tête de ligne au niveau de la couche application et d'améliorer les performances.
HTTP/2 a également introduit une meilleure gestion des erreurs et un meilleur contrôle des flux, ainsi que le server push. La poussée du serveur signifie que le serveur peut envoyer au client des données qui n'ont pas été explicitement demandées, par exemple des ressources dont le serveur pense que le client pourrait avoir besoin. Il notifie d'abord au client ce qu'il a l'intention de pousser et le client peut refuser.
Selon W3Techs HTTP/2 est utilisé par environ 46 % des sites web. Il n'est pas compatible avec les versions précédentes de HTTP.
La troisième version de HTTP, HTTP/3, est conçue pour améliorer les performances de HTTP/2 et résoudre certains problèmes liés à HTTP/2. HTTP/3 utilise l'UDP au niveau de la couche de transport au lieu du TCP. Le blocage des têtes de ligne au niveau de la couche TCP dans HTTP/2 est résolu par l'utilisation de l'UDP. Le blocage en tête de ligne TCP fait référence au scénario dans lequel, si un paquet est perdu, un message est bloqué jusqu'à ce que le paquet puisse être récupéré. L'HTTP/3 permet des connexions plus rapides car il ne s'appuie pas sur les adresses IP. IT utilise des identifiants de connexion afin que les téléchargements soient cohérents même en cas de changement de réseau. Contrairement au TCP, l'UDP n'exige pas qu'un transfert de données soit confirmé avant que la demande suivante ne soit transmise. Les connexions sont également plus rapides car moins de paquets de données doivent être envoyés sur des flux parallèles. Pour établir une connexion, TCP utilise une poignée de main à trois voies. L'UDP crée une connexion en un seul aller-retour. TLS 1.3 étant intégré à HTTP/3, il ne prend en charge que les connexions cryptées (HTTPS).
Les alertes personnalisées et la visualisation des données vous permettent d'identifier et de prévenir rapidement les problèmes de santé et de performance du réseau.
Les en-têtes rendent HTTP extensible car le client et le serveur peuvent convenir d'ajouter de nouveaux noms de champs et de nouvelles informations pour répondre à leurs besoins.
Bien qu'il en ait la possibilité, un serveur HTTP n'est pas tenu de stocker des informations entre les requêtes. Cette caractéristique a rendu les premières versions de HTTP apatrides. Dans les versions antérieures à HTTP/2, les requêtes étaient effectuées de manière indépendante, sans savoir ce qui s'était passé dans les requêtes précédentes. Les requêtes HTTP peuvent être acheminées vers n'importe quel serveur, car celui-ci n'a pas besoin de conserver un état particulier pour un client. Il est donc facile d'adapter le nombre de serveurs à la charge de travail attendue lorsque le maintien d'une connexion persistante nécessiterait des ressources importantes. Lorsqu'il est nécessaire d'interagir avec un site web de manière progressive, par exemple lors d'achats en ligne, HTTP peut utiliser des cookies, des sessions côté serveur, la réécriture d'URL ou des variables cachées pour permettre des sessions avec état Ces solutions de contournement sont appelées fonctions avec état. Un autre avantage de l'absence d'état est que la quantité de données à transférer dans la plupart des cas est réduite au minimum.
L'ensemble de la pile TCP/IP n'est pas sans état. Le TCP au niveau de la couche transport est avec état, il maintient l'état d'une session HTTP et s'assure que les paquets de données perdus peuvent être retransmis.
Le protocole HTTP est généralement considéré comme sans connexion car, une fois que le client a établi une connexion avec un serveur, envoyé une requête et reçu une réponse, la connexion est immédiatement interrompue. HTTP est également considéré comme sans connexion parce que les connexions réseau sont contrôlées au niveau de la couche transport, et non au niveau de la couche application. Le HTTP utilise le TCP, qui est basé sur la connexion, au niveau de la couche transport.
Tant que le client et le serveur savent comment traiter un contenu de données spécifique tel que spécifié par le type MIME dans un en-tête, n'importe quel type de données peut être envoyé via HTTP. MIME signifie Multipurpose Internet Mail Extensions.
Le protocole HTTP est utilisé sur le web chaque fois que des données doivent être transférées entre un client et un serveur, par exemple les API, les services web et les requêtes du navigateur.
HTTP est généralement utilisé par les utilisateurs qui n'ont pas d'informations confidentielles à craindre d'être piratées, qui ne souhaitent pas acheter un certificat SSL ou qui ne veulent pas avoir à gérer la complexité de la maintenance d'un site sécurisé.
Les premières versions de HTTP étaient sans état, mais pas sans session. En règle générale, une session HTTP se déroule en trois étapes, avec quelques variations dans la manière dont les étapes sont gérées dans les différentes versions.
Tout d'abord, le client établit une connexion avec le serveur. Dans la plupart des versions de HTTP, il s'agit d'une connexion TCP, mais HTTP/3 utilise UDP au niveau de la couche de transport.
Ensuite, le client envoie un message de demande pour afficher une page web, par exemple. Une méthode de requête dans le message spécifie l'action que le serveur doit entreprendre. Par exemple, pour visualiser une page web, le client utilisera la méthode GET .
Troisièmement, le serveur traite la demande et renvoie un message de réponse au client, par exemple le contenu de la page web demandée si la demande a abouti, ainsi qu'un code d'état.
Dans les versions HTTP antérieures à HTTP/1.1, la connexion était fermée par défaut une fois la requête HTTP terminée. Si le client souhaitait que la connexion reste ouverte, il devait le spécifier en activant l'en-tête Keep-Alive Connection. Les versions HTTP/1.1 et suivantes permettent au client d'envoyer des messages de requête supplémentaires et la connexion est maintenue en vie par défaut. Ainsi, si un client reçoit un code d'erreur, il peut vouloir réessayer la requête. Si le client souhaite que la connexion soit fermée, il doit le spécifier à l'aide de l'en-tête Close Connection.
Entre le client et le serveur se trouvent de nombreux autres serveurs appelés proxys, qui sont des intermédiaires exécutant des fonctions supplémentaires telles que le cryptage du contenu, la mise en cache et la compression des données, l'équilibrage de charge, la journalisation et la fourniture de connexions partagées pour des utilisateurs simultanés.
Les messages HTTP sont échangés dans un format de type MIME. MIME est une norme pour le courrier électronique qui permet d'étendre le format des demandes de messages afin de prendre en charge des données autres que du texte ASCII brut. Les en-têtes de type MIME dans HTTP ont une fonction similaire ; par exemple, ils permettent à un client de sélectionner l'application appropriée pour ouvrir des fichiers autres que du texte, comme des vidéos, des images, des exécutables, des fichiers audio, etc.
Les requêtes HTTP et les réponses HTTP utilisent le même format de message. Les messages se composent d'une ligne de départ (soit une ligne de requête dans le cas d'un message de requête, soit une ligne d'état dans le cas d'un message de réponse), d'un ou plusieurs champs d'en-tête facultatifs, d'une ligne vide qui indique qu'il n'y a plus de champs d'en-tête, et d'un corps de message facultatif.
La ligne de départ comprend la version du protocole et des informations sur le type de demande, dans le cas d'un message de demande, ou sur le succès ou l'échec de la demande, dans le cas d'un message de réponse.
Les en-têtes HTTP permettent d'inclure des informations supplémentaires sur la requête ou la réponse, telles que la méthode de requête dans le cas des messages de requête et la longueur du contenu renvoyé dans le cas des messages de réponse.
Le corps du message facultatif d'une demande peut inclure les informations qui doivent être téléchargées ou supprimées d'un serveur. Le corps du message facultatif d'une réponse peut inclure le contenu demandé par le client.
L'utilisation d'en-têtes est ce qui rend HTTP flexible et extensible. Un client et un serveur peuvent créer de nouveaux en-têtes pertinents pour une transaction tant qu'ils sont tous deux d'accord sur le format.
Certains en-têtes HTTP sont spécifiques aux messages de requête ou de réponse, par exemple l'en-tête Accept-Language est spécifique aux messages de requête. Cependant, certains en-têtes peuvent apparaître soit dans les requêtes, soit dans les réponses. Par exemple, l'en-tête Content-Type, considéré comme un en-tête de représentation, peut être inclus dans les messages de demande ou de réponse. Dans le premier cas, il indique le type de contenu souhaité par le client. Dans le second, il précise le type de contenu que le serveur renvoie.
Les en-têtes de requête peuvent inclure des informations supplémentaires sur le client et la ressource. Par exemple, l'identificateur de ressource uniforme (URI) est la ressource sur laquelle la méthode doit agir pour obtenir des informations à partir d'un site web spécifique, par exemple. Les en-têtes de requête HTTP peuvent également spécifier des informations sur les données à mettre en cache, des informations générales sur la connexion, des détails sur l'authentification, la date et l'heure, des informations sur le codage du transfert, le format dans lequel les informations peuvent être utilisées pour transférer le contenu, etc.
Les en-têtes de requêteAccept - comme Accept-language et Accept-encoding - et certains en-têtes de représentation complémentaires - comme Content-Language et Content-Encoding - permettent la fonction de négociation de contenu de HTTP. Les en-têtes Accept précisent les préférences du client et les en-têtes de représentation complémentaires dans la réponse précisent ce que le serveur a effectivement renvoyé.
Les en-têtes de réponse peuvent inclure des informations supplémentaires sur le serveur et la ressource. Ils peuvent également indiquer les éventuels cookies, la longueur du contenu renvoyé, le type de contenu, la date de la dernière modification du contenu, etc.
Il existe des en-têtes spéciaux pour de nombreuses fonctions HTTP telles que l'authentification, les types de connexion, le stockage de cookies, le téléchargement de fichiers, la gestion de proxy, la sécurité, l'encodage de transfert, etc.
HTTP est un modèle de communication réseau de type requête-réponse. Son pendant est le modèle publication-abonnement dans lequel un serveur (également appelé courtier) reçoit et distribue des données tandis que le client publie des données au serveur pour les mettre à jour ou s'abonne au serveur pour recevoir des informations. Dans le modèle de publication-abonnement, les données sont automatiquement échangées, mais uniquement lorsqu'elles changent ou si l'information est nouvelle. MQTT est un exemple de protocole de transport qui utilise le modèle publication-abonnement.
Web Real-Time Communication (WebRTC) est utilisé pour effectuer des connexions peer-to-peer (P2P), qui permettent de partager facilement des données d'application et des fichiers multimédias comme l'audio et la vidéo. Facebook Messenger est un exemple d'application qui utilise WebRTC.
QUIC utilise TCP mais est buildé sur UDP. QUIC a été conçu pour réduire la latence dans les transferts de données sur internet et pour résoudre certains problèmes liés à HTTP/2. Google Chrome est un exemple d'application utilisant QUIC.
Le système de fichiers interplanétaire (IPFS) est une alternative récente à HTTP qui possède une architecture P2P distribuée et permet de choisir entre des connexions TCP, QUIC ou WebRTC. Avec son architecture distribuée, il a été conçu pour résoudre les problèmes de défaillance des serveurs qui sont communs aux modèles de protocoles de communication réseau centralisés comme HTTP.
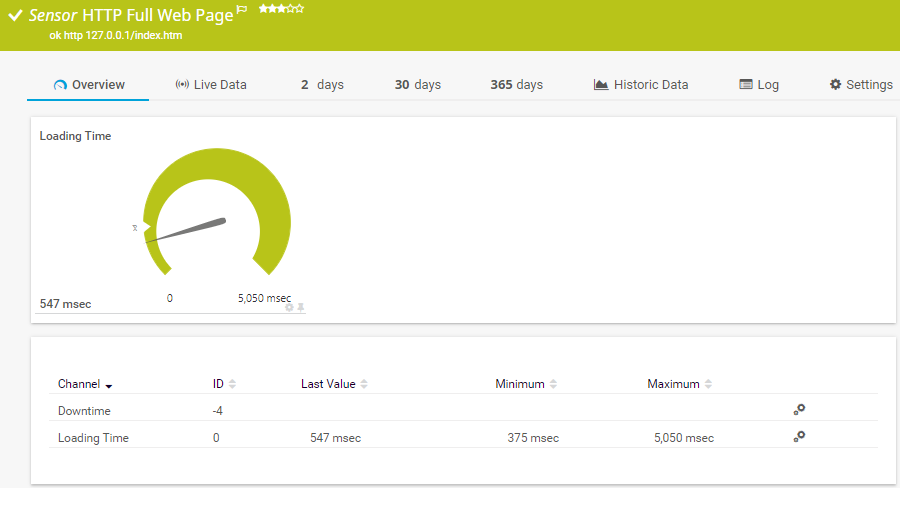
Page Web complète du capteur HTTP
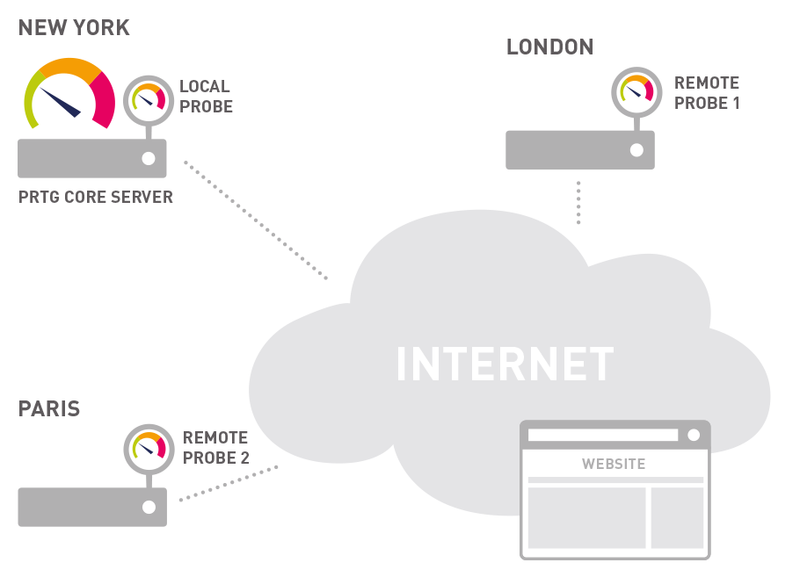
Superviser l'HTTP dans le Cloud
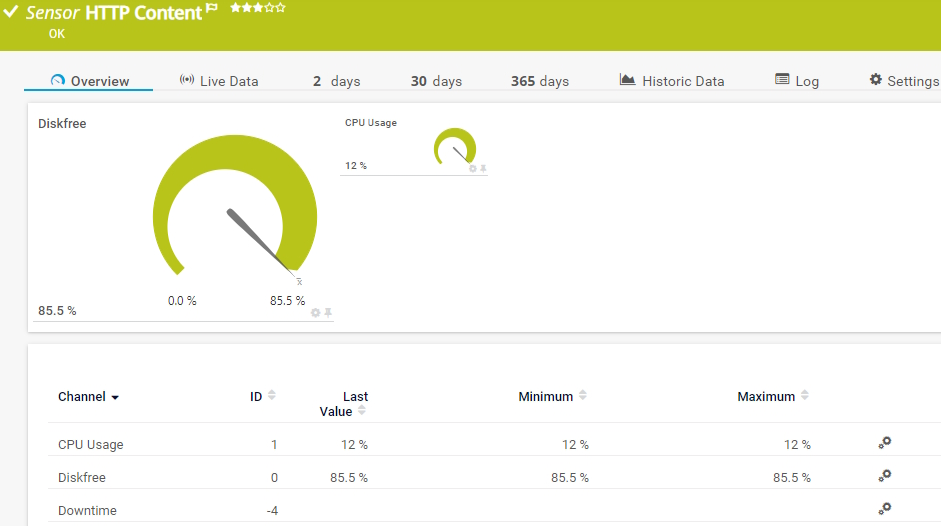
Contenu HTTP du capteur




Le protocole de transfert hypertexte sécurisé (HTTPS) est essentiellement un protocole HTTP crypté ; il "enveloppe" les messages HTTP dans un format crypté. HTTPS utilise Transport Layer Security (TLS) pour crypter les requêtes et les réponses HTTP.
HTTP et HTTPS utilisent des ports différents. En règle générale, HTTP utilise le port 80 et HTTPS le port 443, bien qu'en théorie, n'importe quel port puisse être utilisé, à l'exception de ceux qui sont réservés à des services spécifiques.
Le principal avantage de l'utilisation de HTTPS est l'amélioration de la sécurité. Pour les sites web qui ne transfèrent pas d'informations confidentielles, HTTP pourrait être une option acceptable et moins complexe à mettre en place et à maintenir. En outre, en 2014, Google a annoncé qu'il utiliserait le HTTPS comme signal de classement léger pour encourager les entreprises à passer du HTTP au HTTPS.
L'utilisation du HTTPS au lieu du HTTP présente quelques inconvénients subtils et, dans la pratique, mineurs. Tout d'abord, il peut y avoir une surcharge supplémentaire lors du transfert de données, car il faut d'abord procéder à un échange de données. Deuxièmement, le processus de génération des clés de cryptage peut empêcher le serveur d'effectuer d'autres tâches. Enfin, certains contenus ne peuvent pas être mis en cache localement parce que les données sont cryptées.
Par défaut, HTTP/3 n'est disponible qu'avec HTTPS.
Les notifications en temps réel sont synonymes de dépannage plus rapide afin que vous puissiez agir avant que des problèmes plus graves ne surviennent.

Le TCP est plus fiable mais plus lent que l'UDP. Cependant, lorsque UDP est combiné à QUIC, le résultat est une transmission de paquets rapide et fiable grâce à HTTP/3. HTTP/3 n'en est encore qu'à ses débuts. Au début de l'année 2021, il avait été activé par des applications populaires comme Google, WhatsApp, YouTube et Facebook, mais pas par des applications tout aussi populaires comme Uber ou Twitter.
HTTP/3 est encore un projet de RFC, mais il est pris en charge, selon Wikipédia, par près de 75 % des navigateurs web et, selon W3Techs, par 21 % des 10 premiers millions de sites web pour lesquels W3Techs fournit des données d'utilisation.
La commercialisation d'Internet a entraîné un besoin accru d'analyse et de supervision des réseaux en temps réel afin d'offrir aux entreprises un temps disponible maximal. La supervision et l'analyse des paquets - appelée reniflage de paquets - est la clé pour analyser quels paquets sont perdus, quand et pourquoi, afin de maintenir des performances élevées et constantes.
L'outil de supervision de paquets PTRG supervise et analyse chaque paquet sur votre réseau afin d'identifier la bande passante utilisée, les goulots d'étranglement de la bande passante et les failles de sécurité potentielles. Le renifleur de paquets supervise tout le trafic HTTP, HTTPS, UDP et TCP, ainsi que d'autres trafics de messagerie, de transfert de fichiers, de contrôle à distance et d'infrastructure.
L 'outil de capteurs web de PTRG vous permet de superviser les serveurs web utilisant le protocole HTTP afin de vous assurer que les pages web sont toujours accessibles.
